A-Survey-of-Indexing-Techniques-for-Scalable-Record-Linkage-and-Deduplication.pptx
Settings
Record Linkage and Deduplication
数据匹配(Record Linkage)是指将不同的数据集里相同或相近的东西进行配对。
数据去重(Record Deduplication)是指将一个数据集里相同或相近的东西进行配对以去重。
Record Linkage 在 Statistical agencies、fraud and crime detection 等领域下都可以用到。
Pipline of Record Linkage
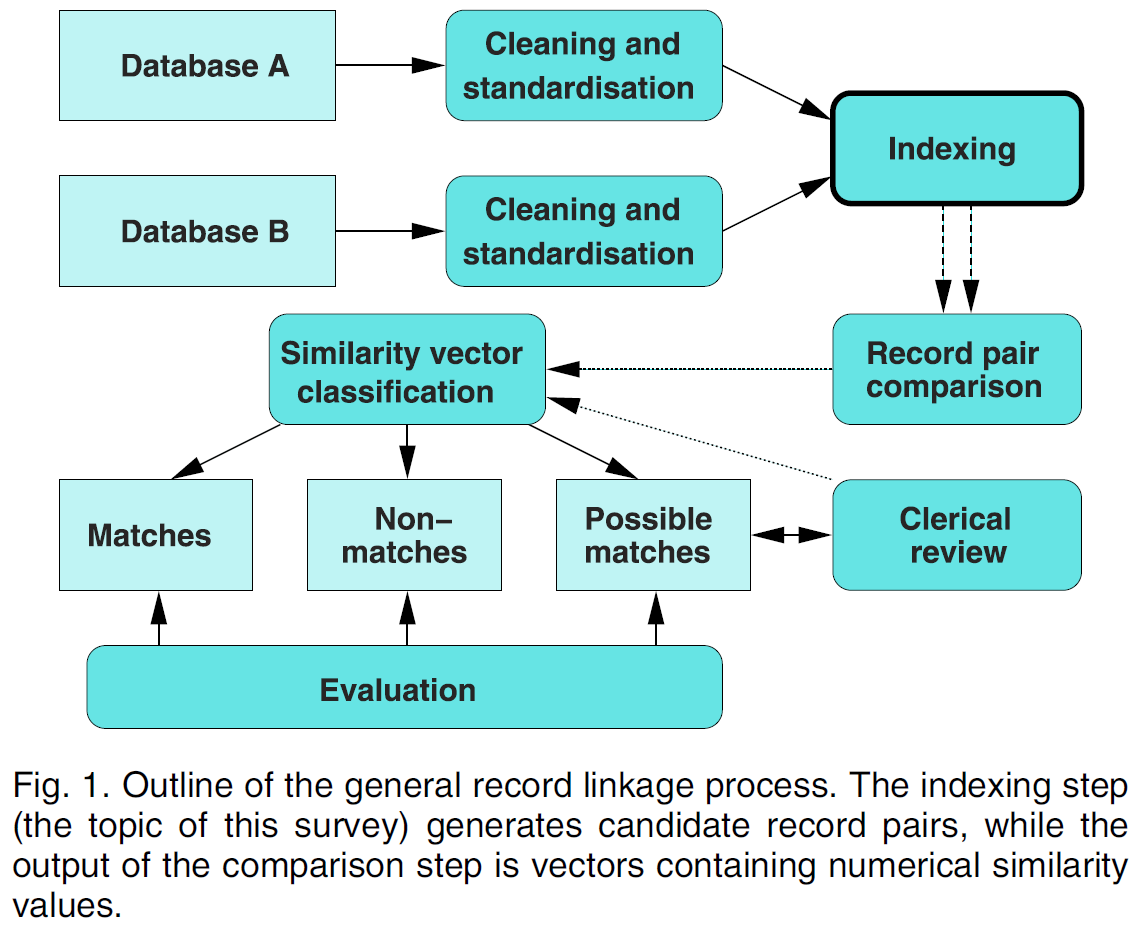
step 1. Pre-process: Data Cleaning and Standardization
处理脏数据、噪声、格式不一致,消除编码格式等的差别
step 2. Indexing
主要目标:让候选对尽可能少,同时还要尽量保留 matches 并且尽量减少 non-matches。(要兼顾时间消耗和匹配的质量)
本文的主要内容是讨论 6 种构建索引的方法及其变种,并进行分析和对比和实验的验证。
一般步骤:
- Build
构建索引,可以是使用类似值域分块的方法,将相似的记录聚成 block。
- Retrieve
生成候选对,可以是在每个块内,分别用块内的记录生成候选对。
step 3. Record Pair Comparison
对候选记录对进行分类,分成 matches, non-matches, possible matches 三类
step 4. Post-process: Evaluation
评估数据匹配的质量和复杂度。
Methods
1 Traditional Blocking
思想:
将相似的记录聚成一个 block,并使用倒排索引来组织记录。
例如对于姓名字段,可以根据发音 (Soundex, NYSII or Double-Metaphone) 来分块。
生成候选对的方法:如果是 Record Linkage 任务,那分别在每个块内部生成候选对,每个块内任选两个属于不同数据集的记录都是候选对。Record Deduplication 类似。

分析:
Traditional Blocking 的复杂度基本上由最大的那个 block 所决定。因此对 Block Key Value 的定义比较敏感。不同的 BKV 定义的方式会影响 block 内记录数量的分布,进而影响该算法的表现。(解决方法:选择合适的 BKV 定义方法。)
2 Sorted Neighborhood Indexing
思想:将所有的记录按照 BKV 排序,然后用一个滑动窗口框住若干个连续的记录,对窗口内的记录生成候选对,然后移动窗口。
本文主要介绍了两种 Sorted Neighborhood Indexing 的实现方法,分别是 Sorted Array-Based Approach 和 Inverted Index-Based Approach。
2.1 Sorted Array-Based Approach
思想:Sorted Neighborhood Indexing 的一种方式,将记录按照 BKV 的字典序排序,然后用一个大小为 w 的窗口去扫,每次往后移动 1 个记录。
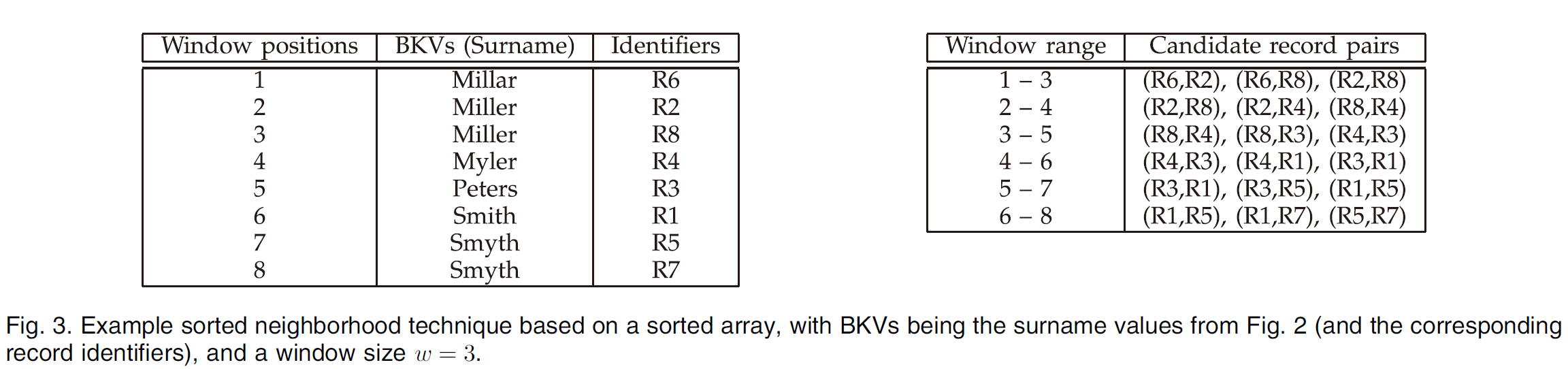
分析:
- 如果窗口选得比较小,而相同 BKV 的记录很多,可能导致有的 matches 不会生成候选对。(解决办法:使用多个属性作为生成 BKV 的依据,这样可以有效避免某个 BKV 记录过多)
- 由于是根据字典序排序的,会对 BKV 的前几个字母比较敏感。例如 “Christina” 和 “Kristina” 在排序后距离会比较远。(解决方法:多用几种 BKV 的定义方法。)
2.2 Inverted Index-Based Approach
思想:和 Traditional Blocking 类似,先根据 BKV 构建倒排索引。然后使用窗口框住 w 个 BKV,对这些 BKV 对应的记录生成候选对。

分析:
- 和 Traditional Blocking 相同,最大的 block 会决定算法的复杂度。
- 和 Sorted Array-Based Approach 类似,对 BKV 的前几个字母比较敏感。
2.3 Adaptive Sorted Neighborhood Approach
思想:不固定窗口的大小,使用合适字符串相似度计算方法,动态确定窗口的大小。
分析:理论分析很困难,所以讨论和使用的较少。
3 Q-Gram-Based Indexing
目标:不仅是对 BKV 相同的记录生成候选对,也对 BKV 相似的记录生成。
思想:对每个 BKV,计算它的所有 q-gram (长度为 q 的子串),然后给定一个阈值 $t\ (t\le 1)$ ,对于所有子串数至少 $l=max(1,\lfloor k\times t\rfloor)$ 的子串组合,将它们按原来的顺序排列形成一个新的 key ,并将这些记录插入到这些 key 对应的 block 里。

分析:
- 正确性高,比前两种方法生成的候选对的数量都多。
- 但是复杂度更高。
4 Suffix Array-Based Indexing
思想:和 Q-Gram-Based Indexing 类似,但是新的 key 是 BKV 的后缀。
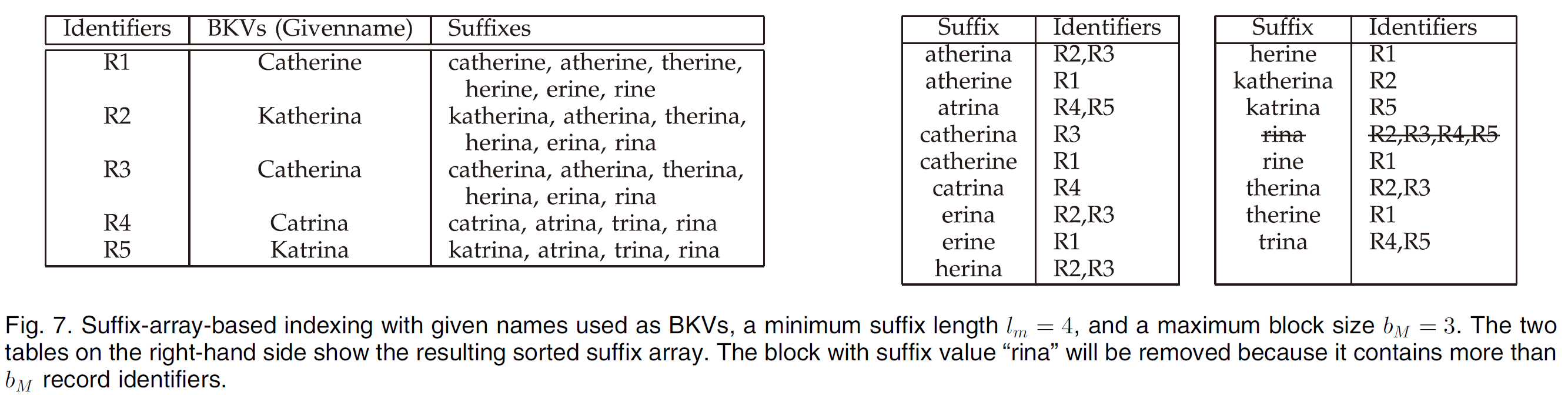
分析:
- 对 BKV 的后缀比较敏感。(解决方法:用子串作为 key。)
4.1 Robust Suffix Array-Based Indexing
思想:将相似度高的后缀串对应的 block 合并起来。
分析:match 的质量相对 Suffix Array-Based Indexing 较高,但是会导致大 block 的产生,代价变大。
5 Canopy Clustering
思想:
- 用 Canopy 聚类 (一种粗糙但快速的聚类算法) 对这些记录进行聚类。
- 这里的 Canopy 聚类基于 tokens (一般是 BKV 的 q-gram)。
- 计算距离可以用 TF-IDF/cosine 方法或者 Jaccard。
5.1 Threshold-Based Approach
思想:
比较原始的 Canopy Clustering 是一种 Threshold-Based Approach
(1) 将数据集向量化得到一个list后放入内存,选择两个距离阈值:T1和T2,其中T1 > T2,对应上图,实线圈为T1,虚线圈为T2,T1和T2的值可以用交叉校验来确定;
(2) 从list中任取一点P,用低计算成本方法快速计算点P与所有Canopy之间的距离(如果当前不存在Canopy,则把点P作为一个Canopy),如果点P与某个Canopy距离在T1以内,则将点P加入到这个Canopy;
(3) 如果点P曾经与某个Canopy的距离在T2以内,则需要把点P从list中删除,这一步是认为点P此时与这个Canopy已经够近了,因此它不可以再做其它Canopy的中心了;
重复步骤(2)、(3),直到list为空结束。
注意:Canopy聚类不要求指定簇中心的个数,中心的个数仅仅依赖于举例度量,T1和T2的选择。

分析:
- 算法的复杂度跟聚类的大小相关。
5.2 Nearest Neighbor-Based Approach
思想:
Nearest Neighbor-Based Approach 是一种变种的 Canopy Clustering.
区别在于将 T1、T2 改成 N1、N2。N1 代表每次将距离最近的 N1 个记录划入聚类;N2 代表每次将距离最近的 N2 个记录从 list 中删除。
分析:
- 也有 Sorted Array-Based Neighborhood Indexing 类似的缺点。(固定聚类大小导致有的 matches 不能生成候选对。)
- 匹配的效果比 Threshold-Based Approach 好,而且更鲁棒。
6 String-Map-Based Indexing
思想:
String-Map-Based Indexing 将 BKV 映射到一个多维欧几里得空间,使得 string 之间的相似度可以用距离度量。然后使用合适的索引(例如 R-tree、grid-based index) 找出相似的 BKV。
疑问1:如何映射。
疑问2:如何确定维度 d。
疑问3:如何生成候选对。
方法的提出者使用方法的是构建两个 R-tree,然后同时自顶向下遍历这两个 R-tree,根据 R-tree 的性质即可找到候选对。
文中提到,由于大部分基于树的索引在 d 增大时性能快速下降。本文使用了一种 grid-based index,将空间分块,在每个维度上分别建立倒排,使用类似 canopy 聚类的方式生成候选对。
分析:
文中还提到,有工作将坐标映射到2d平面中,然后使用 KD-tree 和 nearest neighbor-based similarity approach,可以减少 30% 到 60% 的耗时,并且准确性相当。
Experiments
TODO: finish this part
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 xiongjx751@qq.com